|
PREMIERE PARTIE
NOTIONS DE BASE SUR LE FONCTIONNEMENT DE L'ORDINATEUR |
|
Le microprocesseur est le cœur de l’ordinateur. C’est lui qui est chargé de reconnaître les instructions et de les exécuter (ou de les faire exécuter). Chaque instruction se présente sous la forme d’une suite de bits qu’on représente en notation hexadécimale (exemple : B44C, ou 1011010001001100 en binaire). Une instruction se compose d’un code opérateur (le plus souvent appelé « opcode ») qui désigne l’action à effectuer (B4 dans notre exemple) et d’un « champ d’opérandes » sur lesquelles porte l’opération (ici l’opérande est 4C). Pour travailler, le microprocesseur utilise de petites zones où il peut stocker des données. Ces zones portent le nom de registres et sont très rapides d'accès puisqu'elles sont implantées dans le microprocesseur lui-même et non dans la mémoire vive. Les registres des processeurs INTEL se classent en quatre catégories :
Ils ne sont pas réservés à un usage très précis, aussi les utilise-t-on pour manipuler des données diverses. Ce sont en quelque sorte des registres à tout faire. Chacun de ces quatre registres peut servir pour la plupart des opérations, mais ils ont tous une fonction principale qui les caractérise.
Le registre AX sert souvent de registre d'entrée-sortie : on lui donne des paramètres avant d'appeler une fonction ou une procédure. Il est également utilisé pour de nombreuses opérations arithmétiques, telles que la multiplication ou la division de nombres entiers. Il est appelé « accumulateur ». Exemples d'utilisation :
Le registre BX peut servir de base. Nous verrons plus tard ce que ce terme signifie. Le registre CX est utilisé comme compteur dans les boucles. Par exemple, pour répéter 15 fois une instruction en assembleur, on peut mettre la valeur 15 dans CX, écrire l'instruction précédée d'une étiquette qui représente son adresse en mémoire, puis faire un LOOP à cette adresse. Lorsqu'il reconnaît l'instruction LOOP, le processeur « sait » que le nombre d'itérations à exécuter se trouve dans CX. Il se contente alors de décrémenter CX, de vérifier que CX est différent de 0 puis de faire un saut (« jump ») à l’étiquette mentionnée. Si CX vaut 0, le processeur ne fait pas de saut et passe à l’instruction suivante. Exemple :
Le registre DX contient souvent l'adresse d'un tampon de données lorsqu'on appelle une fonction du DOS. Par exemple, pour écrire une chaîne de caractères à l'écran, il faut placer l’offset de cette chaîne dans DX avant d'appeler la fonction appropriée. Chacun de ces quatre registres comporte 16 bits. On peut donc y stocker des nombres allant de 0 à 65535 en arithmétique non signée, et des nombres allant de –32768 à 32767 en arithmétique signée. Les 8 bits de poids fort d’un registre sont appelés « partie haute » et les 8 autres « partie basse ». Chaque registre est en fait constitué de deux « sous-registres » de 8 bits. La partie haute de AX s’appelle AH, sa partie basse AL. Il en va de même pour les trois autres. En arithmétique non signée, il en découle la formule suivante : AX = AH x 256 + AL ainsi que leurs homologues : BX = BH x 256 + BL CX = CH x 256 + CL DX = DH x 256 + DL Il va de soi qu’en modifiant AL ou AH, on modifie également AX.
Pour stocker un nombre de 32 bits, on peut utiliser des paires de
registres. Par exemple, DX:AX signifie DX x 65535 + AX en
arithmétique non signée. Sur un PC relativement récent, AX, BX, CX, DX ne sont en fait que les parties basses de registres de 32 bits nommés EAX, EBX, ECX, EDX (« E » pour « Extended »). On a donc un moyen plus pratique de stocker les grands nombres. En fait, chaque registre (pas seulement les registres généraux) peut contenir 32 bits.
Ils sont au nombre de quatre :
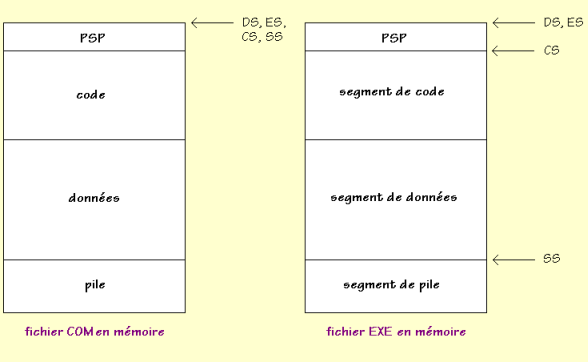
Contrairement aux registres généraux, ces registres ne peuvent servir pour les opérations courantes : ils ont un rôle très précis. On ne peut d’ailleurs pas les utiliser aussi facilement que AX ou BX, et une petite modification de l’un d’eux peut suffire à « planter » le système. Eh oui ! L’assembleur, ce n’est pas Turbo Pascal ! Il n’y a aucune barrière de protection, si bien qu’une petite erreur peut planter le DOS. Mais rassurez-vous : tout se répare très bien en redémarrant l’ordinateur… Dans le registre CS est stockée l’adresse de segment de la prochaine instruction à exécuter. La raison pour laquelle il ne faut surtout pas changer sa valeur directement est évidente. De toute façon, vous ne le pouvez pas. Le seul moyen viable de le faire est d’utiliser des instructions telles que des sauts (JMP) ou des appels (CALL) vers un autre segment. CS sera alors automatiquement actualisé par le processeur en fonction de l’adresse d’arrivée. Le registre DS est quant à lui destiné à contenir l’adresse du segment des données du programme en cours. On peut le faire varier à condition de savoir exactement pourquoi on le fait. Par exemple, on peut avoir deux segments de données dans son programme et vouloir accéder au deuxième. Il faudra alors faire pointer DS vers ce segment. ES est un registre qui sert à adresser le segment de son choix. On peut le changer aux mêmes conditions que DS. Par exemple, si on veut copier des données d’un segment vers un autre, on pourra faire pointer DS vers le premier et ES vers le second. Le registre SS adresse le segment de pile. Il est rare qu’on doive y toucher car le programme n’a qu’une seule pile. Intéressons-nous à présent aux valeurs que le DOS donne à ces registres lors du chargement en mémoire d’un fichier exécutable ! Elles diffèrent selon que le fichier est un programme COM ou EXE. Pour écrire un programme en assembleur, il est nécessaire de connaître ce tableau par cœur :
Le schéma suivant montre mieux la situation :
Dans un fichier EXE, le header indique au DOS les adresses initiales de chaque segment
par rapport au début du programme (puisque le
compilateur n'a aucun moyen de connaître l'adresse à laquelle le programme sera chargé).
Lors du chargement, le DOS ajoutera à ces valeurs l'adresse
d'implantation pour obtenir ainsi les véritables adresses de segment.
Remarque : Pourquoi DS et ES pointent-ils vers le PSP dans le cas d’un fichier EXE ? Première raison : pour que le programmeur puisse accéder au PSP ! Deuxième raison : parce qu'un programme EXE peut comporter un nombre quelconque de segments de données. C'est donc au programmeur d'initialiser ces registres, s'il veut accéder à ses données.
Les voici :
Le registre IP désigne l’offset de la prochaine instruction à exécuter, par rapport au segment adressé par CS. La combinaison de ces deux registres (i.e. CS:IP) suffit donc à connaître l’adresse absolue de cette instruction. Le processeur peut alors aller la chercher en mémoire et l’exécuter. De plus, il actualise IP en l’incrémentant de la taille de l’instruction en octets. Tout comme CS, il est impossible de modifier IP directement. Le registre SP désigne le sommet de la pile. Il faut bien comprendre le fonctionnement de la pile, aussi allons-nous insister sur ce point. La pile ne peut stocker que des mots. On appelle un mot (« word » en anglais) un nombre codé sur deux octets (soit 16 bits). Prenons un exemple simple : un programme COM. Le segment de pile (adressé par SS) et le segment de code ne font qu’un. Avant l’exécution, SP vaut FFFE. C’est l’offset de la dernière donnée de 16 bits empilée, par rapport à SS bien sûr. Pourquoi FFFE ? Tout simplement parce que la pile se remplit à l’envers, c’est-à-dire en partant de la fin du segment et en remontant vers le début. Le premier mot empilé se trouve à l’offset FFFE. Il tient sur deux octets : l’octet FFFE et l’octet FFFF. Mais comment se fait-il qu’un mot soit déjà empilé avant le début du programme ? Ce mot est un zéro que le DOS place sur la pile avant l’exécution de tout programme COM. Nous en verrons la raison plus tard. A présent, que se passe-t-il si à un instant quelconque une instruction ordonne au processeur d’empiler un mot ? Eh bien le stack pointer sera décrémenté de 2 et le mot sera copié à l’endroit pointé par SP. Rappelez-vous que la pile se remplit à l’envers ! C’est pour cette raison que SP est décrémenté à chaque empilage et non pas incrémenté. Un petit exemple pour rendre les choses plus concrètes : PUSH AX L’effet de cette instruction est d’empiler le mot contenu dans le registre AX. Autrement dit, SP est automatiquement décrémenté de 2, puis AX est copié à l’adresse SS:SP. Lors du dépilage, le mot situé au sommet de la pile, c’est-à-dire le mot adressé par SS:SP, est transféré dans un registre quelconque choisi par le programmeur, après quoi le stack pointer est incrémenté de 2. Exemple : POP BX Cette fois, on retire le dernier mot empilé pour le placer dans le registre BX. Evidemment, SP sera incrémenté de 2 aussitôt après. La pile est extrêmement utile lorsqu’il s’agit de stocker provisoirement le contenu d’un registre qui doit être modifié. Exemple :
Il est important de comprendre qu’on ne peut dépiler que le mot qui se trouve au sommet de la pile. Le premier mot empilé est le dernier qui sera dépilé. La pile doit être manipulée avec une extrême précaution. Un dépilage injustifié fait planter la machine presque systématiquement. Les trois derniers registres sont beaucoup moins liés au fonctionnement interne du processeur. Ils sont mis à la disposition du programmeur qui peut les modifier à sa guise et les utiliser comme des registres généraux. Comme ces derniers cependant, ils ont une fonction qui leur est propre : servir d’index (SI et DI) ou de base (BP). Nous allons expliciter ces deux termes. Dans la mémoire, les octets se suivent et forment parfois des chaînes de caractères. Pour utiliser une chaîne, le programmeur doit pouvoir accéder facilement à tous ses octets, l’un après l’autre. Or pour effectuer une opération quelconque sur un octet, il faut connaître son adresse. Cette adresse doit en général être une constante évaluable par le compilateur. Pourquoi une constante ? Parce que l’adresse est une opérande comme les autres, elle se trouve immédiatement après l’opcode et doit donc avoir une valeur numérique fixe ! Prenons un exemple : MOV AH, [MonOctet] Pas de panique ! Cette instruction en assembleur signifie « Mettre dans AH la valeur de l’octet adressé par le label MonOctet ! ». A la compilation, “MonOctet” sera remplacé par la valeur numérique qu'il représente et on obiendra alors une instruction en langage machine telle que : 8A260601 8A26 est l’opcode (hexa) de l’instruction “MOV AH, [constante quelconque]”, et 0601 est l’offset de “MonOctet”. Il serait pourtant fastidieux, dans le cas d’une chaîne de 112 caractères, de traiter les octets avec 112 instructions dans lesquelles seule l’adresse changerait. Il faudrait pouvoir faire une boucle sur l’adresse, mais alors celle-ci ne serait plus une constante, d’où le problème. Pour les constructeurs du microprocesseur, la seule solution était de créer de nouveaux opcodes pour chaque opération portant sur un octet en mémoire. Ces opcodes spéciaux feraient la même action que ceux dont ils seraient dérivés, mais l’adresse passée en paramètre serait alors considérée comme un décalage par rapport à un registre spécial. Il suffirait donc de faire varier ce registre, et le processeur y ajouterait automatiquement la valeur de l’opérande pour obtenir l’adresse réelle ! C’est à cela que servent SI, DI et BP. Par exemple : MOV AH, [MonOctet + DI] sera codé : 8AA50601 8AA5 est l’opcode pour l’instruction “MOV AH, [constante quelconque + DI]”. Remarque : les registres SI et BP auraient tout aussi bien pu être employés, mais pas les registres généraux, SAUF BX. En effet, BX peut jouer exactement le même rôle que BP. N’oubliez pas que BX est appelé registre de « base », et que BP signifie « Base Pointer. » Nous verrons la différence entre une base et un index lorsque nous commencerons l’assembleur.
Un programme doit pouvoir faire des choix en fonction des données dont il dispose. Pour cela, il lui faut par exemple comparer des nombres, examiner leur signe, découvrir si une erreur a été constatée, etc… Il existe à cet effet de petits indicateurs, les flags qui sont des bits spéciaux ayant une signification très précise. De manière générale, les flags fournissent des informations sur les résultats des opérations précédentes. Ils sont tous regroupés dans un registre : le registre des indicateurs. Comprenez bien que chaque bit a un rôle qui lui est propre et que la valeur globale du registre ne signifie rien. Le programmeur peut lire chacun de ces flags et parfois modifier leur valeur directement. En mode réel, certains flags ne sont pas accessibles. Nous n’en parlerons pas. Nous ne commenterons que les flags couramment utilisés. Nous verrons quelle utilisation on peut faire de ces indicateurs dans la troisième partie de ce tutoriel.
CF
(« Carry Flag ») est l’indicateur
de retenue. Il est positionné à 1 si et seulement si
l’opération précédemment effectuée
a produit une retenue. De nombreuses fonctions du DOS l’utilisent
comme indicateur d’erreur : CF passe alors à 1 en
cas de problème.
Remarque : Les notations CF, PF, AF, etc… ne sont pas reconnues par l’assembleur. Pour utiliser les flags, il existe des instructions spécifiques que nous décrirons plus tard.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||